
แก้ไขโดย IP: การปรับปรุงความเป็นส่วนตัวและลดการละเมิดความเป็นส่วนตัว/การปรับปรุงเครื่องมือ
ความเป็นมา
เป้าหมายของเราสำหรับโครงการนี้มีอยู่สองส่วนหลัก ดังนี้
- ประการแรก เพื่อป้องกันโครงการของเราจากการก่อกวน, คุกคาม, หุ่นเชิด, ผู้ก่อกวนต่อเนื่องยาวนาน, การบิดเบือนข้อมูล, และพฤติกรรมก่อกวนอื่น ๆ
- ประการที่สอง เพื่อปกป้องผู้แก้ไขที่ไม่ลงทะเบียนของเราจากการกดขี่ข่มเหง, การล่วงละเมิด และการละเมิดโดยไม่เผยแพร่ที่อยู่ไอพีของพวกเขา
จากการอภิปรายร่วมกันของเราบนหน้าโครงการและที่อื่น ๆ แล้วพบว่า เรากำลังใช้งานหมายเลขไอพีเพื่อจุดประสงค์ดังนี้
- มีประโยชน์เป็นอย่างมากต่อการตรวจสอบความ "ใกล้เคียง" ของผู้แก้ไข ที่อาจแก้ไขในห้วงไอพีเดียวกันหรือใกล้เคียงกัน
- ใช้เพื่อตรวจสอบประวัติการแก้ไขของผู้ใช้ที่ไม่ได้เข้าสู่ระบบ
- เพื่อเป็นการตรวจสอบการมีส่วนร่วมข้ามวิกิของผู้ใช้
- ใช้เพื่อดูว่าผู้ใช้ได้แก้ไขโดยผ่าน VPN หรือ Tor หรือไม่
- ใช้เพื่อตรวจสอบว่าการแก้ไขนั้นมาจากตำแหน่งใด และใช้ตรวจสอบว่าอาจเป็นหน่วยงานธุรกิจ มหาวิทยาลัย หรือหน่วยงานราชการ
- ที่อยู่ไอพีสามารถใช้คัดกรองเบื้องต้นเกี่ยวกับการมีประวัติก่อกวนตัวเนื่องยาวนาน
- ใช้งานโดยตัวกรองการละเมิดเกี่ยวกับแสปมบางชนิด
- สำคัญสำหรับการใช้การบล็อคช่วงไอพี
ด้วยเหตุเหล่านี้มีผลต่อการดูว่ามีการใช้บัญชีผู้ใช้สองบัญชีโดยบุคคลเดียวกันหรือไม่ บางครั้งเรียกว่าการตรวจจับหุ่นเชิด
การใช้ที่อยู่ไอพีเพื่อเป็นการตรวจจับหุ่นเชิดกลายเป็นขั้นตอนการที่มีข้อบกพร่องมาก เมื่อที่อยู่ไอพีกำลังเพิ่มมากขึ้นตามจำนวนอุปกรณ์และจำนวนบุคคลที่ออนไลน์มากขึ้น อีกทั้งที่อยู่ IPv6 มีความซับซ้อนและอยากต่อการตรวจจับช่วงไอพี สำหรับผู้มาใหม่ส่วนใหญ่ ที่อยู่ไอพีที่ดูเหมือนจะเป็นตัวเลขสุ่มและดูเหมือนจะไม่สมเหตุสมผล อีกทั้งยังยากต่อการจำและการนำไปใช้งาน
ต้องใช้เวลาและความพยายามอย่างมากสำหรับผู้ใช้ใหม่ เพื่อการทำความคุ้นเคยกับการใช้ที่อยู่ไอพีสำหรับการกระทำต่าง ๆ เช่นขอให้บล็อคหรือการกรอง
ดังนั้น เราจึงมีความคิดที่จะลดการพึ่งพาที่อยู่ไอพี และสร้างเครื่องมือใหม่ ๆ ที่ใช้แหล่งข้อมูลที่หลากหลายมากขึ้นเพื่อการจับคู่ผู้ใช้ เพื่อการปิดที่อยู่ไอพีและไม่ให้ส่งผลต่อการทำงานของโครงการมากนัก
การแนะนำแนวคิดสำหรับเครื่องมือใหม่
เราต้องการจะให้ผู้ใช้รับข้อมูลจากไอพีได้ง่ายและสะดวกต่อการจดจำมากขึ้น ดังนั้น เราจึงวางแผนในการสร้างเครื่องมือหรือฟีเจอร์เพื่อรองรับการใช้งานนี้

1. ฟีเจอร์ข้อมูลไอพี
This feature is currently a work in progress. To follow along, please visit: IP Info Feature.
มีข้อมูลสำคัญบางอย่างที่ที่อยู่ไอพีให้ เช่น ' ตำแหน่ง, องค์การ ความเป็นไปได้ของจุด Tor/VPN, rDNS, ช่วงที่ระบุไว้ เป็นต้น ปัจจุบันหากผู้แก้ไขต้องการดูข้อมูลนี้ ที่อยู่ไอพีพวกเขาจะใช้เครื่องมือภายนอกหรือเครื่องมือค้นหาเพื่อดึงข้อมูลนั้น เราสามารถลดความซับซ้อนของกระบวนการนี้ได้โดยการเปิดเผยข้อมูลนั้นแก่ผู้ใช้ที่เชื่อถือได้บนวิกิ ในอนาคตที่ที่อยู่ไอพีถูกปิดบัง จะแสดงต่อไปสำหรับชื่อผู้ใช้ที่ถูกปกปิด
ข้อกังวลหนึ่งที่เราได้ยินจากผู้ใช้ที่เราเคยพูดคุยด้วยคือมันไม่ง่ายเสมอไปที่จะบอกได้ว่า IP นั้นมาจาก VPN หรืออยู่ในบัญชีดำ บัญชีดำมีความเปราะบาง – บางรายการไม่ได้รับการอัปเดตมากนัก, บางรายการอาจทำให้เข้าใจผิดได้ เราสนใจที่จะทราบว่าในสถานการณ์ใดบ้างที่จะช่วยให้คุณทราบว่าไอพีนั้นมาจาก VPN หรืออยู่ในบัญชีดำ และคุณจะค้นหาข้อมูลนั้นได้อย่างไรในตอนนี้
ข้อดี:
- ลดความยุ่งยากของการตรวจสอบไอพีสำหรับผู้ใช้
- เราคาดว่าสิ่งนี้จะช่วยลดเวลาการเรียกข้อมูลได้มาก
- ในระยะยาว จะลดการพึ่งพาที่อยู่ไอพี ที่ยากต่อความเข้าใจ
ความเสี่ยง:
- จากสถานการณ์ในตอนนี้ เรามีความเสี่ยงที่จะเปิดเผยข้อมูลเกี่ยวกับ IP ให้กับกลุ่มคนที่มีขนาดใหญ่กว่ากลุ่มผู้ใช้ที่จำกัด ซึ่งก็คือข้อดีของการใช้ที่อยู่ไอพีเป็นตัวระบุ
- ขึ้นอยู่กับผู้ให้บริการไอพีของเรา เราอาจไม่ได้แปลภาษาของข้อมูล และอาจแสดงเป็นภาษาอังกฤษ
- มีความเป็นไปได้ว่าบริษัทหรือโรงเรียนอยู่เบื้องหลังการแก้ไข มากกว่าเป็นบุคคลคนเดียว
2. การหาผู้แก้ไขที่ใกล้เคียงกัน
To detect sockpuppets (and unregistered users), editors have to go to great lengths to figure out if two users are the same. This involves comparing the users’ contributions, their location information, editing patterns and much more. The goal for this feature will be to simplify this process and automate some of these comparisons that can be made without manual labor.
This would be done with the help of a machine learning model that can identify accounts demonstrating a similar behavior. The model will be making predictions on incoming edits that will be surfaced to checkusers (and potentially other trusted groups) who will then be able to verify that information and take appropriate measures.
We could potentially also have a way to compare two or more given unregistered users to find similarities, including seeing if they are editing from nearby IPs or IP ranges. Another opportunity here is to allow the tool to automate some of the blocking mechanisms we use – like automatic range detection and suggesting ranges to block accordingly.
A tool like this holds a lot of possibilities—from identifying individual bad actors to uncovering sophisticated sockpuppeting rings. But there is also a risk of exposing legitimate sock accounts who want to keep their identity secret for various reasons. This makes this project a tricky one. We want to hear from you about who should be using this tool and how can we mitigate the risks.
With the help of the community, such a feature can evolve to compare features that editors currently use when comparing editors. One possibility is also to train a machine learning model to do this (similar to how ORES detects problematic edits).
Here’s one possibility for how such a feature might look in practice:
-
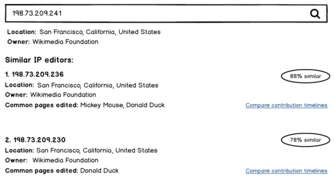 Finding similar editors with IPs
Finding similar editors with IPs -
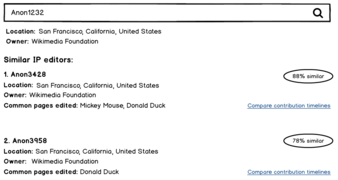 Finding similar editors with masked IPs
Finding similar editors with masked IPs


ประโยชน์:
- Such a tool would greatly reduce the time and effort from our functionaries to find bad-faith actors on our projects.
- This tool could also be used to find common ranges between known problem editors to make blocking IP ranges easier.
ความเสี่ยง:
- If we use Machine Learning to detect sockpuppets, it should be very carefully monitored and checked for biases in the training data. Over-reliance on the similarity-index score should be cautioned against. It is imperative that human review be part of the process.
- Easier access to information such as location can sometimes make it easier, not more difficult, to find identifiable information about someone.
3. A database for documenting long-term abusers
Long-term abuse vandals are manually documented on the wikis, if they're documented at all. This includes writing up a profile of their editing behaviors, articles they edit, indicators for how to recognize their sock accounts, listing out all the IP addresses used by them and more. With numerous pages spanning the IP addresses used by these vandals, it is increasingly a mammoth task to search through and find relevant information when needed, if it is available. A better way to do this could be to build a database that documents the long-term abusers.
Such a system would facilitate easy cross-wiki search for documented vandals matching search criteria. Eventually, this could potentially be used to automatically flag users when their IPs or editing behaviors are found to match those of known long-term abusers. After the user has been flagged, an admin could take necessary action if that seems appropriate. There is an open question about whether this should be public or private or something in-between. It is possible to have permissions for different levels of use for read and write access to the database. We want to hear from you about what would you think would work best and why.

Cost:
- Such a database would need community members to participate in populating it with the currently known long-term abusers. This can be a significant amount of work for some wikis.
Benefits:
- Cross-wiki search for documented long-term abusers would be an enormous benefit over the current system, reducing a lot of work for patrollers.
- Automated flagging of potentially problematic-actors based on known editing patterns and IPs would come in handy in a lot of workflows. It would allow admins to make judgements and actions based on the suggested flags.
Risks:
- As we build such a system, we would have to think hard about who has access to the database data and how we can keep it secured.
These ideas are at a very early stage. We want your help with brainstorming on these ideas. What are some costs, benefits and risks we might be overlooking? How can we improve upon these ideas? We’d love to hear from you on the talk page.
Existing tools used by editors
On-wiki tools
- CheckUser: CheckUser allows a user with a checkuser flag to access confidential data stored about a user, IP address, or CIDR range. This data includes IP addresses used by a user, all users who edited from an IP address or range, all edits from an IP address or range, User agent strings, and X-Forwarded-For headers. Most commonly used for detecting sockpuppets.
- Allow checkusers to have access to which users have over 50 accounts on the same email. The existence of those was confirmed in phab:T230436 (although the task itself is irrelevant). While this does not affect the IP privacy directly, it could slightly mitigate the effect of harder abuse management.
Project-specific tools (including bots and scripts)
Please specify what project the tool is used on, what it does and include link if possible
External tools
ToolForge tools
- Intersect contribs
- WHOIS and reverse DNS
- Editor interaction analyser – Analyse interactions between two or three users – activity on same pages, during the same time etc.
- IPCheck: Allows you to look up information about an IP address including if it is a a proxy, tor node or potential VPN.
- GUC – Global user contributions for any user.
- Reverse DNS for a range
Third-party tools
- Major IP address blocks: http://www.nirsoft.net/countryip/cz.html
- User agent string lookup: http://www.useragentstring.com/
- Nmap
- Spamhaus lists and XBL (Exploits blacklist)
- Talos – IP reputation (mainly for email spam)